
以孔夫子旧书网(http://www.kongfz.com/1004/)为例:
一.网站结构
1.网站截图说明
该网站为列表结构,可以通过识别列表的方式对全篇数据进行抽取。
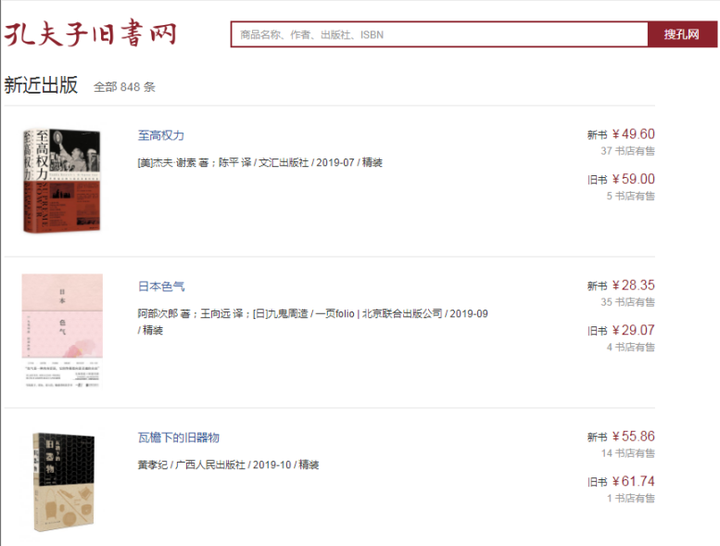 网站列表页
网站列表页
2. 采集结果截图
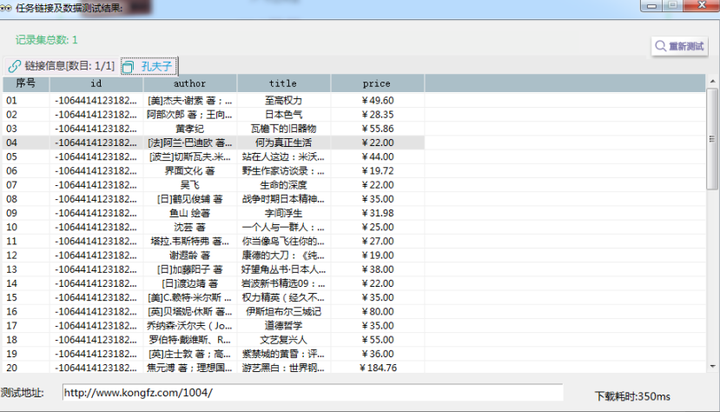 采集数据结果
采集数据结果
二. 配置模板
- 新建任务
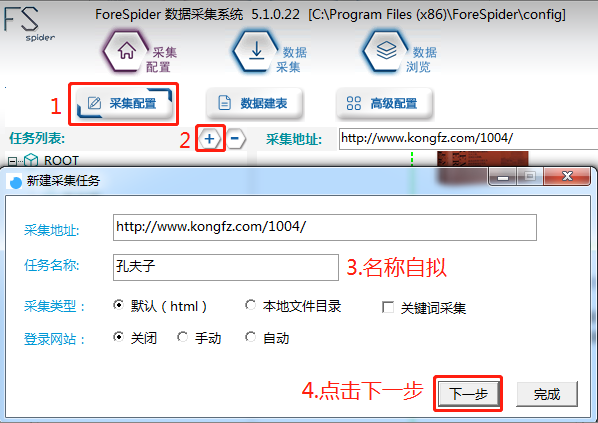 新建任务
新建任务
点击【下一步】,需要采集每一页检索结果并抽取数据,所以此处需要勾选【普通翻页】和【数据抽取】,如图:
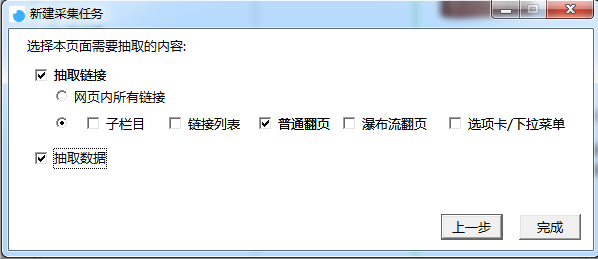 新建采集任务
新建采集任务
2.创建/选择表单
①创建表单
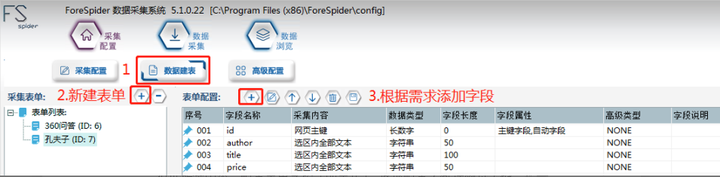 创建表单
创建表单
②配置表单
根据所需内容,配置表单字段(即表头),此处配置了包括网页主键、作者名称、标题名称、价格等四个字段, 以配置发布时间(pubtime)为例:
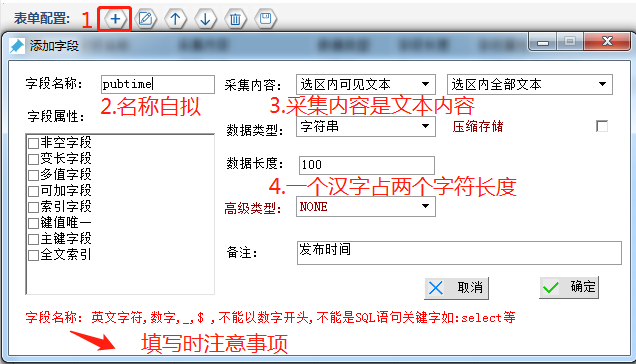 配置表单
配置表单
③数据抽取链接关联表单
选择刚才新创建的表单"孔夫子"
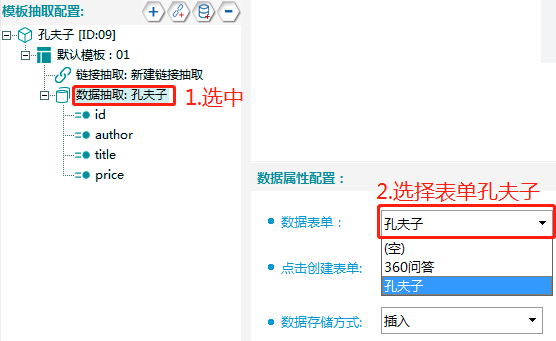 关联表单
关联表单
3.字段定位
取值方法:由于此处活取的是列表页的数据,所以可以应用“识别列表”功能,直接取到列表数据,操作方法如下:
①点击“数据抽取-孔夫子”,按住ctrl+鼠标左键点击定位标题内容
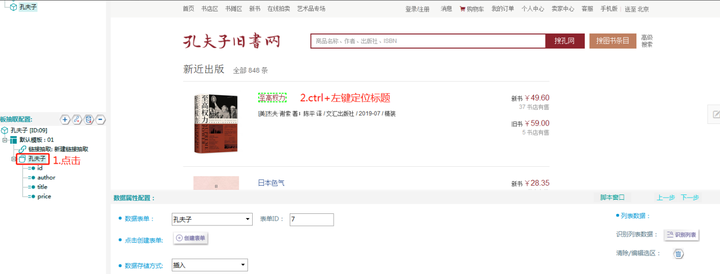 定位标题
定位标题
②按住Shift+鼠标左键继续点击,直到点击到选中整个第一条数据
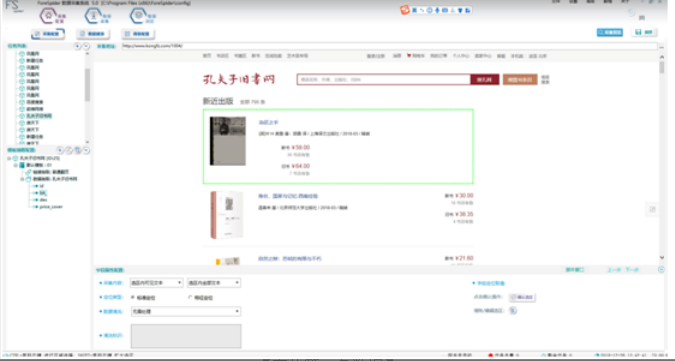 定位第一条数据
定位第一条数据
③在软件的右下角可以看到“识别列表”按钮 ,此时点击“识别列表”,如下图,此时列表中的内容都已经选中。
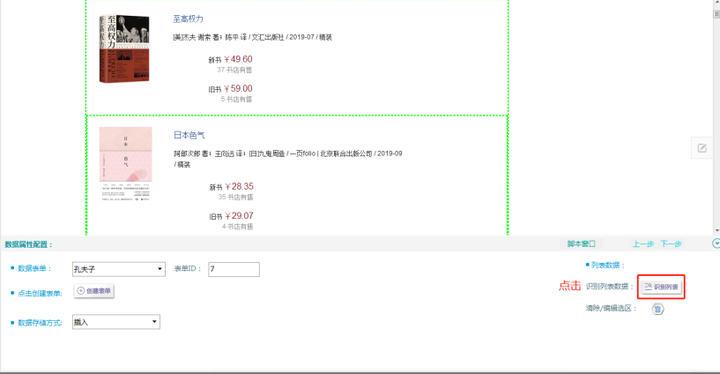 定位全数据
定位全数据
④对每个字段进行取值,方法依然是:按住Ctrl+鼠标左键,进行区域选择,按住Shift+鼠标左键,扩大选择区域。如:price字段,见下图:
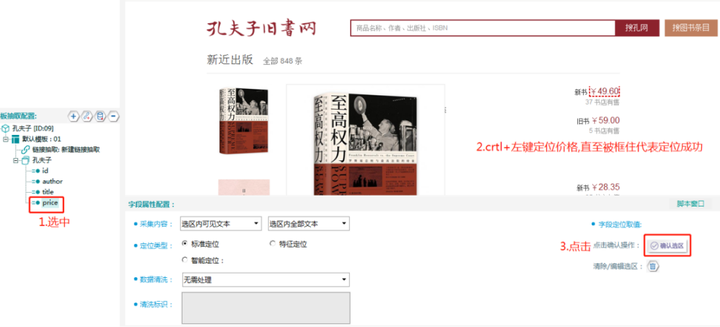 字段定位
字段定位
4.模板预览
鼠标右键点击“孔夫子”,然后点击“模板预览”
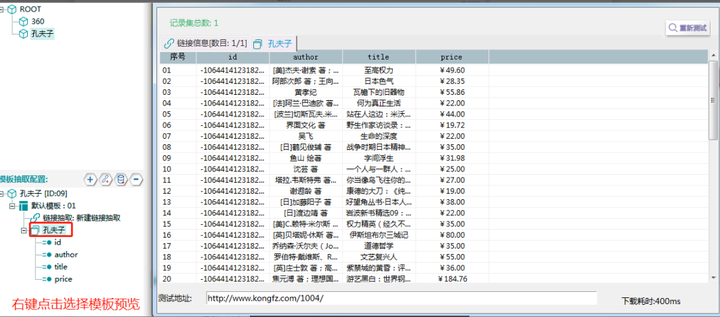 模板预览
模板预览
5.过滤翻页链接
勾选标题过滤,过滤规则选择包含,填入"下一页"
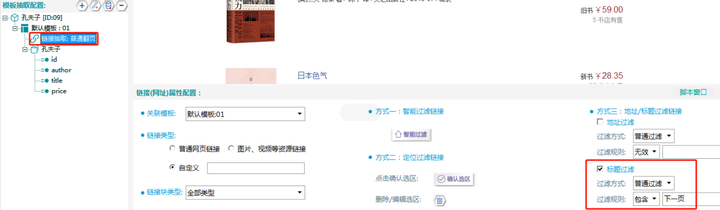 过滤翻页
过滤翻页
三.数据采集
1.连接数据库
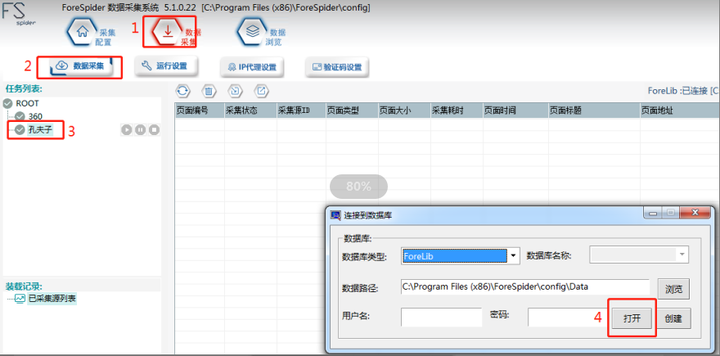 连接数据库
连接数据库
2.创建数据表
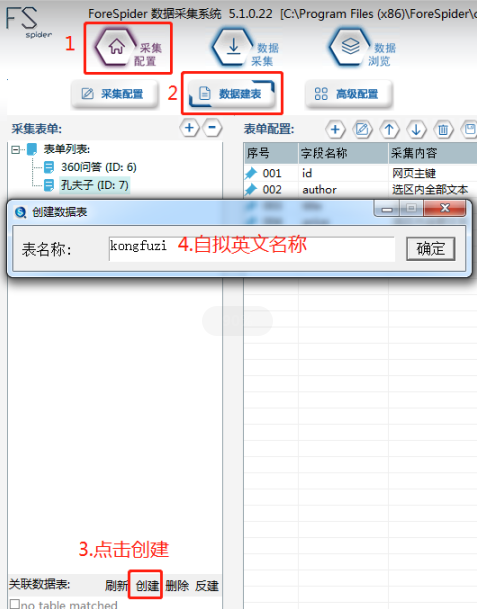 创建数据表
创建数据表
3.选中数据表
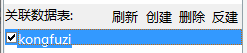 关联数据表
关联数据表
4.开始采集
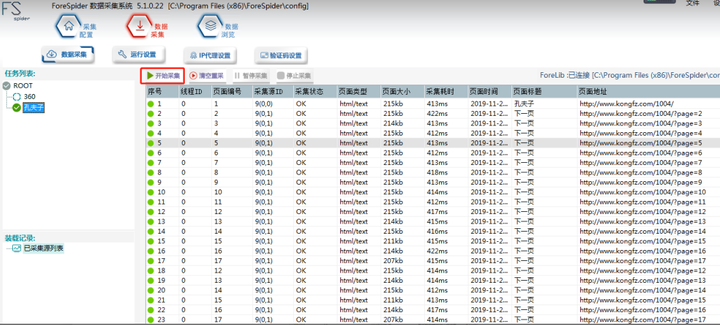 开始采集
开始采集
5.采集结果
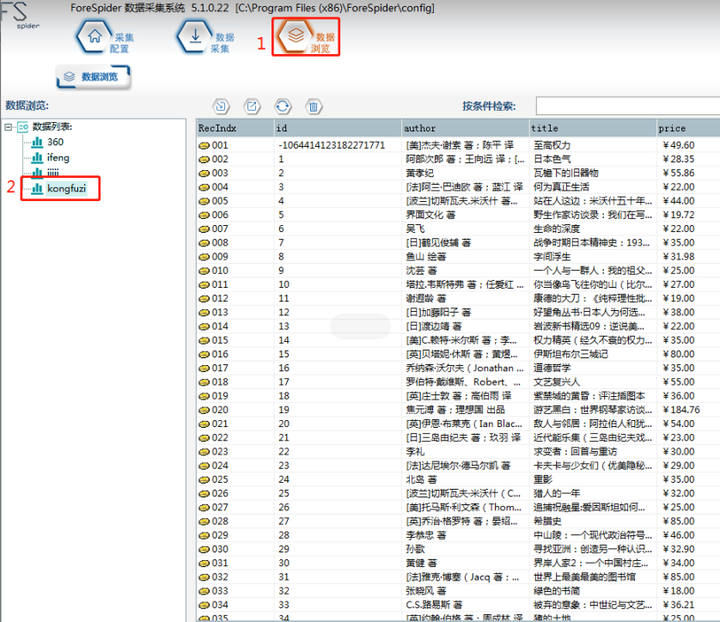 采集结果
采集结果



相关推荐
通过对拿到的数据进行数据质量分析,检查原始数据中存在的脏数据,通过查看原始数据中抽取的数据,发现存在数据缺失的现象,使用朗格拉日插值法:选取缺失值前5个数据作为前参考组,缺失值后5个数据作为后参考组,...
2020语言与智能技术竞赛:事件抽取任务2020语言与智能技术竞赛:事件抽取任务2020语言与智能技术竞赛:事件抽取任务2020语言与智能技术竞赛:事件抽取任务2020语言与智能技术竞赛:事件抽取任务2020语言与智能技术...
elasticsearch或kafka的数据抽取工具:logstash-5.6.1,版本5.6.1,可实现全量或增量的数据抽取,有需要可自行下载~
本项目内容包括数据采集、知识存储、知识抽取、知识计算、知识应用五大部分 数据采集 本次项目主要采集构建了两个知识图谱和一个关系抽取数据集 人物知识图谱:主要包含各个人物的信息 关系抽取数据集:标注出...
(1)Kettle数据抽取---全量抽取
Kettle实现Oracle两表之间进行增量抽取数据,不需要时间戳!
事件抽取数据集事件抽取数据集事件抽取数据集
针对怎样提高自动抽取列表页数据的准确率和适应性进行了研究。在研究已有的多数据区域挖掘算法和数据记录识别算法的基础上,针对列表页数据记录组织方式的多样性改进了数据记录识别算法,提高了识别数据记录的准确率...
ChatIE:通过多轮问答问题实现实命名实体识别和关系事件的零样本信息抽取,并在NYT11-HRL等数据集上超过了全监督模型 零样本信息抽取(Information Extraction,IE)旨在从无标注文本中建立IE系统,因为很少涉及...
离线数据处理 任务一:数据抽取
复赛数据 2021 数据抽取挑战赛复赛数据 2021 数据抽取挑战赛复赛数据 2021 数据抽取挑战赛复赛数据 2021 数据抽取挑战赛复赛数据 2021 数据抽取挑战赛复赛数据 2021 数据抽取挑战赛复赛数据 2021 数据抽取挑战赛复赛...
3) 融合多种实体抽取工具; 姓名属性不够精确 1) 性别判断难度比较大, 模型的准确率有限; 2) 需要融入规则字典来解决常用名的性别识别; 匹配策略亟待优化 1) 采用实体-代词依赖词、上下文相似度; 2) 需要考虑其他更多...
中文自然语言的实体抽取和意图识别(Natural Language Understanding),可选Bi-LSTM CRF 或者 IDCNN CRF
句子级事件抽取任务采用DuEE1.0数据集,包含65个已定义好的事件类型约束和1.7万中文句子。数据集分为以下5个部分: 事件类型约束:共定义了65个事件类型及其对应的121个论元角色类别。 训练集:共1.2万个句子,...
其中本软件产品提供了数据抽取、数据清洗、数据转换、数据校验、数据补丁等数据操作主要功能。 数据抽取,即将源数据库表抽取到目标数据库,数据表结构不变; 数据清洗,即整理、清洗需要转换的源数据。 ...
基于Pytorch的命名实体识别-信息抽取python源码(支持中英文数据+LSTM+CRF等多种模型)+数据集.zipdata文件夹中有三个开源数据集可供使用,玻森数据 (https://bosonnlp.com) 、1998年人民日报标注数据、MSRA微软亚洲...
kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 kettle抽取MySQL 增量数据 到 ES中 ...
篇章级事件抽取任务采用DuEE-fin数据集,包含13个事件类型的1.17万个篇章。数据集分为以下5个部分: 事件类型约束:共定义了13个事件类型及其对应的92个论元角色类别。 训练集:约7000个篇章,包含其中对应的事件...
Connotate:Web数据抽取神器 网页数据抽取 非结构化数据抽取与分类分析 共15页.pdf
本文围绕数据采集在大数据中的应用展开研究,重点分析 了大数据的概念、数据采集的方式方法与如何用Python来进行数据采集。 关键词: 大数据;互联网;信息;数据采集 中图分类号: TP212.9;TN929.5;; ;文献标识码: A;...