
фЛЅщщшЕЗчЙфИцхАшЏДчНфИяМhttps://www.qidian.com/яМчцАцЎхшЁЈчцАцЎфИКфОяМ
фИ.чНчЋчЛц
1.чНчЋцЊхОшЏДц
щщшЕЗчЙфИцчНфИчцшПцДцАцАцЎхшЁЈфИчцАцЎяМхІфИхОцчЄКяМ
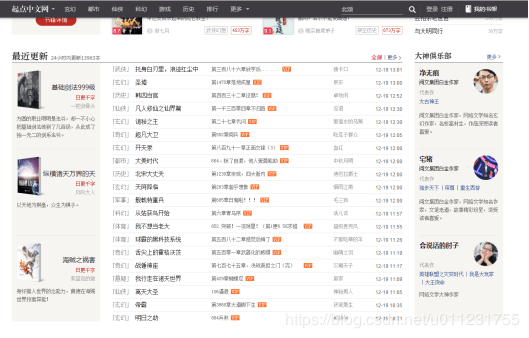
ухшЁЈцАцЎщЁЕщЂу
2.щщчЛццЊхО
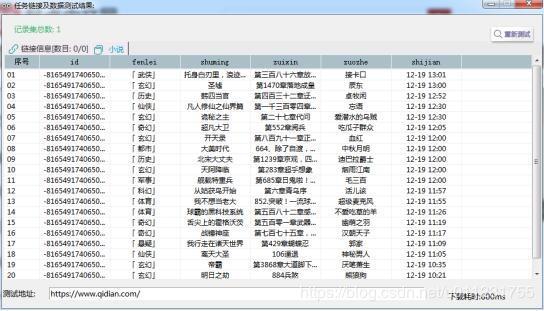
ущщхКцЅчхшЁЈцАцЎу
фК.щ чНЎцЈЁцП
- цАхЛКфЛЛхЁ
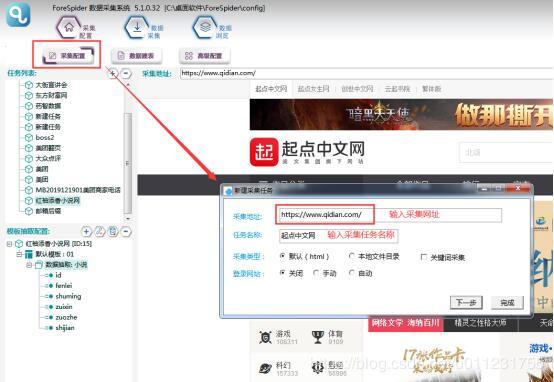
чЙхЛфИфИцЅяМчБфКфЛ щшІщщцЌщЁЕщЂшЁЈц МцАцЎяМцфЛЅхОщуцНщцАцЎуу
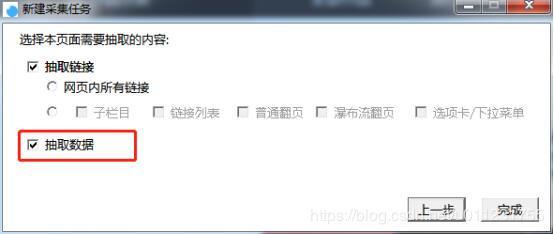
2.ххЛК/щцЉшЁЈх
шЁЈхххЛКххЏфЛЅщхЄщцЉфНПчЈяМхІцхЗВцхЛКхЅНчшЁЈхяМщцЉхЏЙхКцАцЎшЁЈххГхЏухІццВЁцяМчЙхЛххЛКшЁЈху
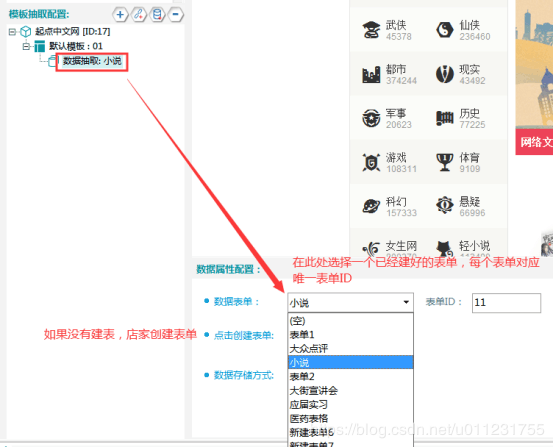
уххЛКшЁЈху
ц ЙцЎцщх хЎЙяМщ чНЎшЁЈххцЎЕяМцЄхЄщ чНЎфКidяМфИЛщЎяМуfenleiяМхАшЏДчБЛхЋяМуshumingяМхАшЏДхчЇАяМуzuixinяМццАчЋ шяМуzuozheяМфНш яМуshijianяМцДцАцЖщДяМчхцЎЕу
цГЈцяМщщшЁЈц М/хшЁЈцАцЎцЖяМidяМфИЛщЎяМшЎОчНЎчцЖхяМщцЉшЊхЂфИЛщЎу=>яМхцЎЕххБцЇфЛчЛяМ
цЙхМфИяМхПЋщхЛКшЁЈуяМчЙхЛуххЛКшЁЈхухКчАхМЙчЊуяМ
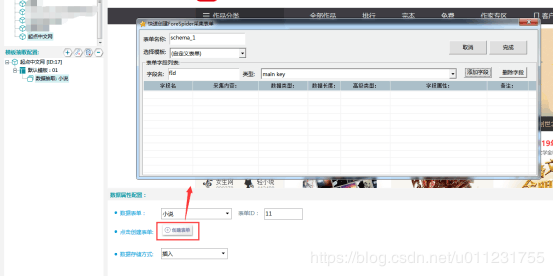
ущ чНЎшЁЈху
цЙхМфКяМшЊчБхЛКшЁЈуяМхЈуцАцЎхЛКшЁЈучщЂуяМ
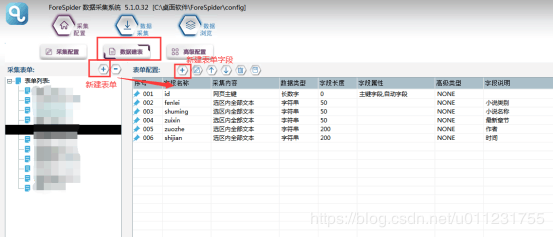
ущ чНЎшЁЈху
4.шЏхЋхшЁЈ
щфИшЁЈххяМchrl+чЙхЛшЁЈхЄДчЌЌфИфИЊшЁЈц МяМхshift+чЙхЛх ЖфЛшЁЈхЄДцЉхЄЇщхяМчДшГццшЁЈхЄДхшЂЋщфИяМцхчЙхЛшЏхЋхшЁЈу
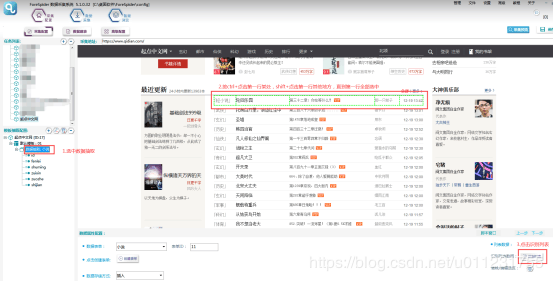
ушЏхЋхшЁЈу
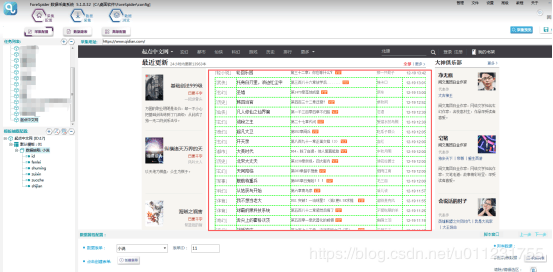
ухшЁЈшЏхЋцху
5.хцЎЕххМ
т fenleiяМщшПхцЎЕхЎфНххМяМцctrl+ххЛц щЂяМчЁЎшЎЄщху
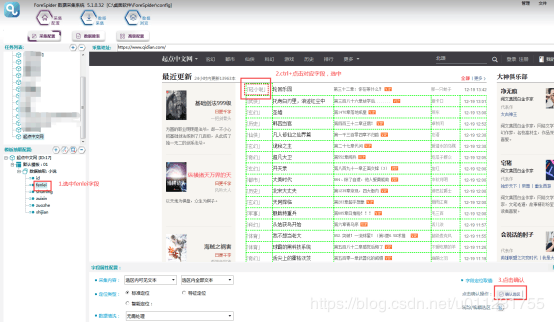
тЁshumingяМщшПхцЎЕхЎфНххМяМцctrl+ххЛц щЂяМчЁЎшЎЄщху
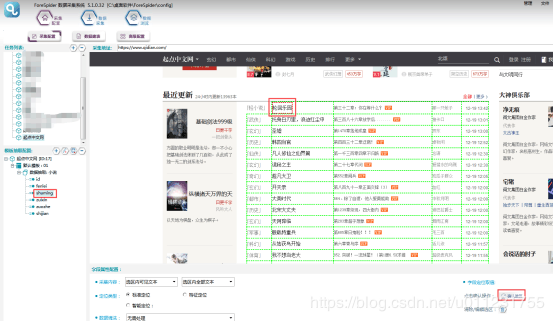
Т
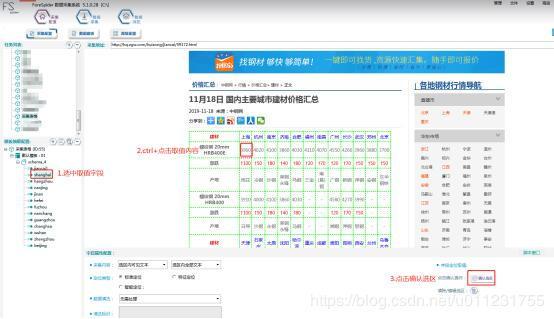
тЂх ЖфЛхцЎЕцч Їхц ЗчцЙцГшПшЁхцЎЕххМу
6.х ГшцАцЎшЁЈ
х ххЛКфИфИЊцАцЎшЁЈяМхІфИхОцчЄК
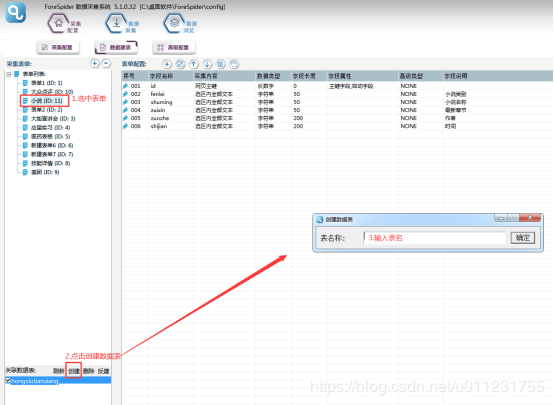
хх ГшшЁЈхяМхОщцАцЎшЁЈу
7.цЈЁцПщЂшЇ
чЙхЛщщщЂшЇяМшПшЁщЂшЇу
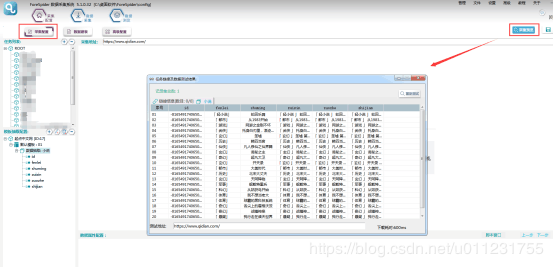
ущщщЂшЇу
фИ.цАцЎщщ
- шПшЁшЎОчНЎ
шПшЁшЎОчНЎхЄхЏфЛЅшЎОчНЎщщщхКІущщччЅуфЛЛхЁшЃ шННчу
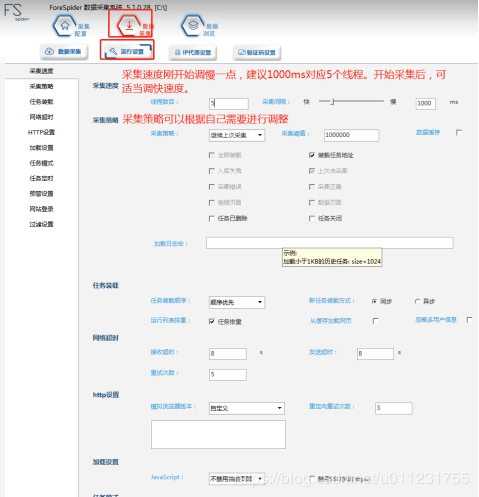
ушПшЁшЎОчНЎу
2.щцЉщщфЛЛхЁ
хЈуфЛЛхЁхшЁЈуфИхОщщшІщщчфЛЛхЁяМхЏхОщхЄфИЊфЛЛхЁяМхцЖщщу
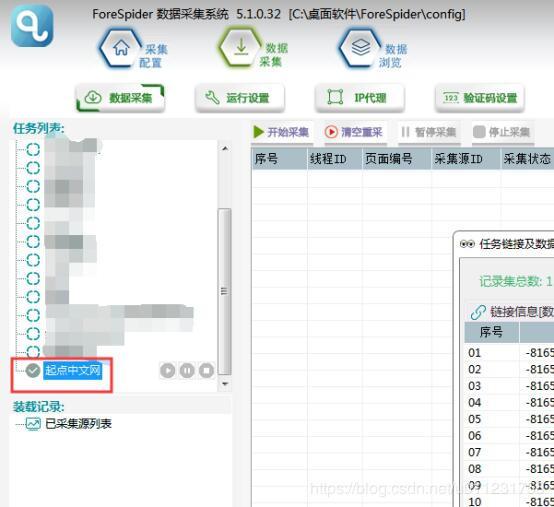
ущцЉщщфЛЛхЁу
3.хМхЇщщ
чЙхЛухМхЇщщуяМчГЛчЛхМхЇшПшЁщщухЉфНфЛЛхЁцАфИК0цЖяМчГЛчЛшЊхЈхцЂщщучЈцЗфЙхЏфЛЅшЊхЗБцхфЛЛхЁцхцЂфЛЛхЁяМхцЂфЛЛхЁфМщцОфЛЛхЁяМхцЌЁхЏхЈцЖщцАшЃ шННфЛЛхЁяМу
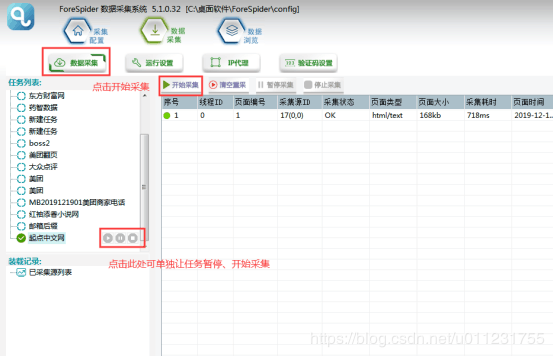
ухМхЇщщу
4.цАцЎцЕшЇ
щщфИцЎЕцЖщДфЛЅхяМчЙхЛуцАцЎцЕшЇуяМхЈцАцЎхшЁЈфИщфИхЏЙхКчцАцЎшЁЈяМхГхЏцЕшЇщщхАчцАцЎяМчЙхЛухЗцАуцщЎхЏфЛЅхцЅцОчЄКцАцЎу
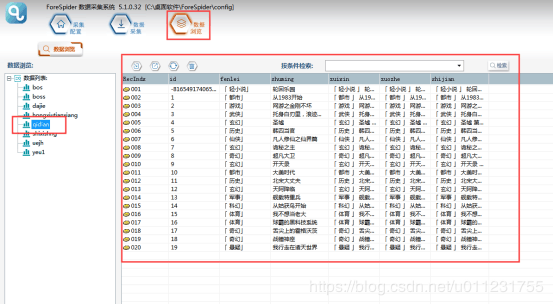
уцАцЎцЕшЇу
5.хЏМхКцАцЎ
чЙхЛухЏМхКуцщЎяМщцЉхЏМхКцфЛЖц МхМхфПху
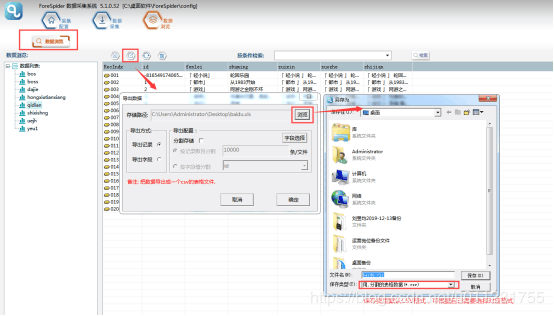
ухЏМхКцАцЎу



чИх ГцЈш
хЄЇцАцЎфИцАцЎщщхЄЇцАцЎфИцАцЎщщ
хЄЇцАцЎшцЏфИхЎЁшЎЁцАцЎщщццЏфИцЙцГчч чЉЖ.docxхЄЇцАцЎшцЏфИхЎЁшЎЁцАцЎщщццЏфИцЙцГчч чЉЖ.docxхЄЇцАцЎшцЏфИхЎЁшЎЁцАцЎщщццЏфИцЙцГчч чЉЖ.docxхЄЇцАцЎшцЏфИхЎЁшЎЁцАцЎщщццЏфИцЙцГчч чЉЖ.docxхЄЇцАцЎшцЏфИхЎЁшЎЁцАцЎ...
хЄЇцАцЎхЎцDemoчГЛчЛ-MaxComputeцАцЎфЛхКцАцЎшНЌцЂхЎшЗЕ.pdf хЄЇцАцЎхЎцDemoчГЛчЛ-MaxComputeцАцЎфЛхКцАцЎшНЌцЂхЎшЗЕ.pdf хЄЇцАцЎхЎцDemoчГЛчЛ-MaxComputeцАцЎфЛхКцАцЎшНЌцЂхЎшЗЕ.pdf хЄЇцАцЎхЎцDemoчГЛчЛ-MaxComputeцАцЎфЛхК...
хЄЇцАцЎцЅцКцАцЎщщшЏІц хшЁЈхО-PPTцЈЁцП.pptx
фИчЇщЂххЄЇцАцЎфИЛхЈщВхОЁчфНцшцАцЎщщцЙцГ.pdf
324щЁЕ11фИхцАхцПхКцКц ЇцПхЁхЄЇцАцЎшЕцКхЙГхАухЄЇцАцЎхКхКЇуцАцЎцВЛчуцАцЎшЕцКфИхПхЛКшЎОцЙцЁ.docx
хЄЇцАцЎфИцАцЎццхЄЇцАцЎфИцАцЎцц
хЄЇцАцЎхМх+цАцЎццЏ+цАцЎщщцЙцГ+цАцЎхццЛхЛяМ хЄЇцАцЎхМхцЏцфИчГЛхфИщЈщхЏЙхЄЇшЇцЈЁцАцЎщшПшЁццчЎЁчххцчццЏцДЛхЈфИхЗЅчЈхЎшЗЕухЎцЖЕчфКфЛцАцЎчщщуххЈущЂхЄчухцхАчЛцхчАчхЎцДчхНхЈцяМцЈхЈ...
фИчЇщЂхЄЇцАцЎчГЛчЛфИхЄЇшЇцЈЁцАцЎщхццчЈ хЄЇцАцЎцццчЈ 2_хЄЇцАцЎчшцЏфИшЖхП х Б7щЁЕ.pdf
хЄЇцАцЎццЏхфКЋ ц чКПхЄЇцАцЎ ццКчЇЛхЈчЋЏхЄЇцАцЎхЎшЗЕ цАцЎщщфИхц х Б21щЁЕ.pptx
35хЅщцЉщЂчЎяМхЄЇцАцЎцЖцущЋцЇшНуцАцЎцВЛчщЂчЎ.docxяМхЄфЙ хКцЌчЅшЏчЙхП хЄ
хЄЇцАцЎхЎцЖцАцЎщщцЖц
щЂххЄЇцАцЎчшЎЁщцАцЎщщфИхКчЈч чЉЖ.docx
хЄЇцАцЎчшЎЁщцАцЎщщфИхКчЈхц.docx
щшЗЏхЎЂшПхЄЇцАцЎхЙГхАчцАцЎщщццЏч чЉЖ.pdf
ухЎцДшЏОчЈхшЁЈу HadoopхЎщЊцфНцх-1 х Б20щЁЕ.pdf HadoopхЎщЊцфНцх-2 х Б73щЁЕ.pdf хЎцДч фИцЕЗшДЂчЛхЄЇхІMEMшЏОчЈ хЄЇцАцЎфИфКшЎЁчЎццЏцчЈ хЄЇцАцЎхЄчхЙГхАхццЏ 10-хЄЇцАцЎшЏОчЈцЛчЛяМх Б9щЁЕяМ.pdf хЎцДч фИцЕЗшДЂчЛ...
ухЄЇцАцЎуцАфЛ5.0фИхЁцАцЎухЄЇцАцЎуцАфЛ5.0фИхЁцАцЎухЄЇцАцЎуцАфЛ5.0фИхЁцАцЎухЄЇцАцЎуцАфЛ5.0фИхЁцАцЎухЄЇцАцЎуцАфЛ5.0фИхЁцАцЎухЄЇцАцЎуцАфЛ5.0фИхЁцАцЎухЄЇцАцЎуцАфЛ5.0фИхЁцАцЎухЄЇцАцЎуцАфЛ5.0фИхЁцАцЎ...
щшхЄЇцАцЎфКЇцшххЎщЊхЎшЎфИхПщЁЙчЎхЛКшЎОцЙцЁ.pdf